MedNAS: Multi-scale training-free neural architecture search for medical image analysis
Yan Wang, Liangli Zhen*, Jianwei Zhang, Miqing Li, Lei Zhang, Zizhou Wang, Yangqin Feng, Yu Xue, Xiao Wang, Zheng Chen, Tao Luo, Rick Siow Mong Goh, and Yong Liu
IEEE Transactions on Evolutionary Computation, 2024
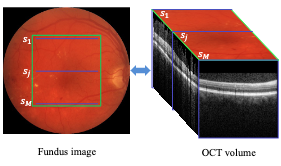
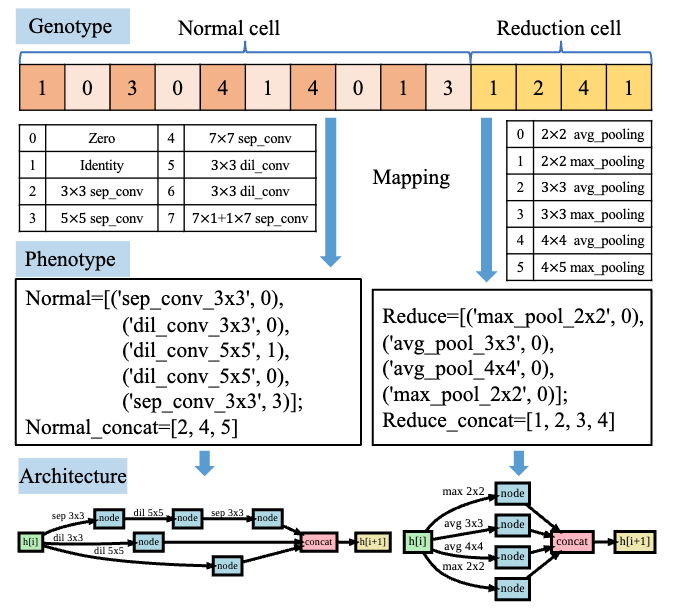
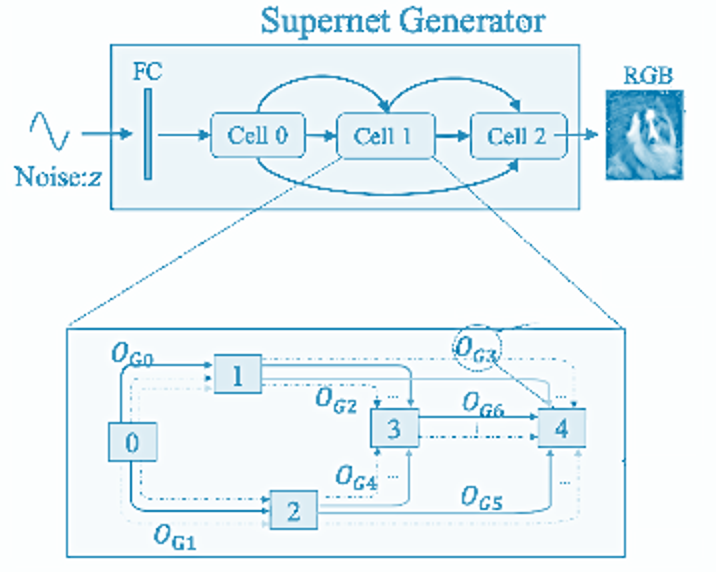
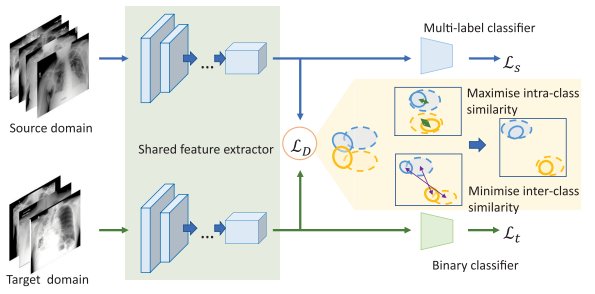
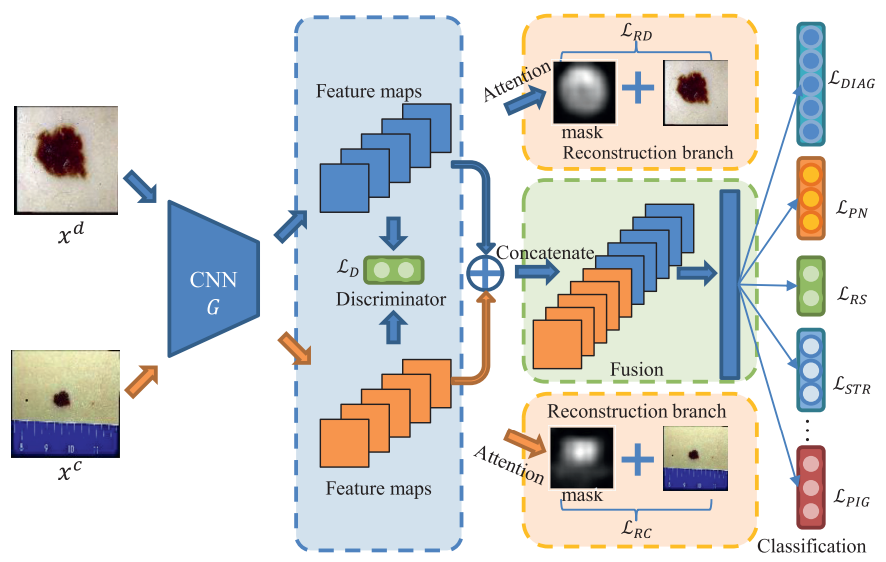
Deep neural networks have demonstrated impressive results in medical image analysis, but designing suitable architectures for each specific task is expertise-dependent and time-consuming. Neural architecture search (NAS) offers an effective means of discovering architectures. It has been highly successful in numerous applications, particularly in natural image classification. Yet, medical images possess unique characteristics, such as small regions and a wide variety of lesion sizes, that differentiate them from natural images. Furthermore, most current NAS methods struggle with high computational costs, especially when dealing with high-resolution image datasets. In this paper, we present a novel evolutionary neural architecture search method called Multi-Scale Training-Free Neural Architecture Search to address these challenges. Specifically, to accommodate the broad range of lesion region sizes in disease diagnosis, we develop a new reduction cell search space that enables the search algorithm to explicitly identify the optimal scale combination for multi-scale feature extraction. To overcome the issue of high computational costs, we utilize training-free indicators as performance measures for candidate architectures, which allows us to search for the optimal architecture more efficiently. More specifically, by considering the capability and simplicity of various networks, we formulate a multi-objective optimization problem that involves two training-free indicators and model complexity for candidate architectures. Extensive experiments on a large medical image benchmark and a publicly available breast cancer detection dataset are conducted. The empirical results demonstrate that our MSTF-NAS outperforms both human-designed architectures and current state-of-the-art NAS algorithms on both datasets, indicating the effectiveness of our proposed method.


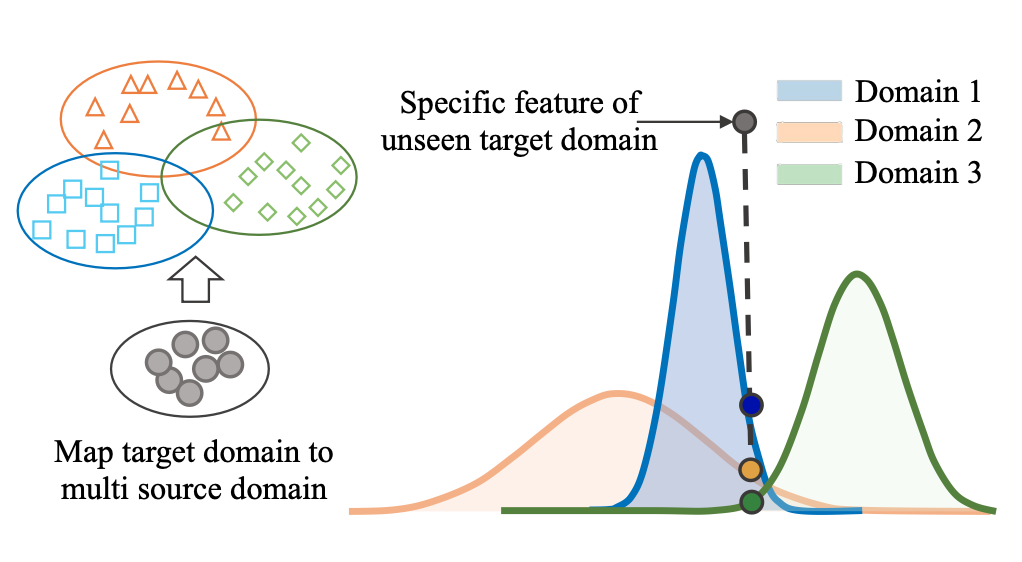

 Neural architecture search with progressive evaluation and sub-population preservationIEEE Transactions on Evolutionary Computation, 2024
Neural architecture search with progressive evaluation and sub-population preservationIEEE Transactions on Evolutionary Computation, 2024